








.png)
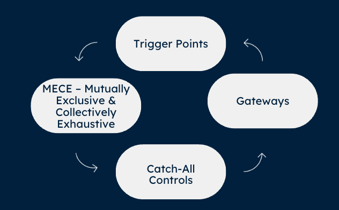
The 4 Control Concepts
Achieving SOC 2 Compliance requires Control Activities to meet the Trust Services Criteria. There are Four Control Concepts to Consider in Your Controls.
Updated: Sep 20
There's four (4) control concepts to apply a holistic approach to effective business operations and achieve SOC 2 and ISO 27001 success.
 Controls are a new concept for many tech companies. In the earlier stages of a start-up, growth is favoured over control — there’s no point controlling something if it’s not viable as a business. Controls are often seen as applying the brakes: it takes resources and management focus to design, implement and operate controls. It’s a myth that controls need to be a drain on resources. Well-designed controls support efficient and robust operations. In many cases, they free up resources from being more proactive in managing the business processes in an effective way.
Controls are a new concept for many tech companies. In the earlier stages of a start-up, growth is favoured over control — there’s no point controlling something if it’s not viable as a business. Controls are often seen as applying the brakes: it takes resources and management focus to design, implement and operate controls. It’s a myth that controls need to be a drain on resources. Well-designed controls support efficient and robust operations. In many cases, they free up resources from being more proactive in managing the business processes in an effective way.To develop controls in a fit-for-purpose way, there are four control concepts. When audit firms and consultants are brought in, they often jump to recommending the types of controls they see in larger companies that they are used to. They often don’t fit the smaller scale, innovative, agile nature of the tech industry. Considering the following concepts in a practical and context-dependent way will support an effective internal control framework.
Trigger Points
The biggest point of failure is the lack of a clear trigger point to initiate "controls" (required actions). It's like a missed tripwire; the corresponding event or action doesn't take place as it should. An ironic example I've seen before, is someone who had a comprehensive to-do list to track all their responsibilities but forgot to look at the to-do list.
In the most effective processes, trigger points are automated or implied by design, which prevents them from being missed. This can include system workflows, periodic recurring meetings and automated notifications (eg. system monitoring tools). A common point of failure for SOC reports is when an employee is terminated, but there’s no trigger to initiate removal of their building and system access (or even payroll). The other one we see all the time is incident management and customer requests that fail to be effectively logged and managed.
When people say things “fall by the wayside” or “slip through the cracks”, it’s usually because of a non-existent or ineffective trigger point.
Gateways
A gateway is the concept of needing to pass minimum criteria, like a key for a lock. An important example of this is system development. Ensuring the testing, approvals and communication processes are performed appropriately before releasing software changes to the live environment.
In the earlier stages of a startup, this is often done on a best-efforts basis, and the decision is made to go live once the functionality broadly meets what is needed.
A lack of clear gateway criteria (including non-functional requirements) builds up technical debt in the form of poor quality code, security vulnerabilities, bugs, etc. As the engineering team grows —with more junior developers and a higher volume of developers — these problems increase exponentially.
A gateway is about defining the minimum criteria that need to be satisfied. A well-defined process will allow for some exceptions to the rule, but the process itself will ensure it is an exception and doesn't become a common pathway just because it's easier. For example, an emergency change or "hot-fix" may not be viable to pass all the same steps prior to deploying a chance. There may be an approval process to override the standard criteria in that instance, or it may be checked retrospectively.
Catch-All Controls
Even very well-thought-out and clearly defined processes cannot account for every future event that may occur. This makes catch-all controls extremely important.
In some client-focused organisations, the customer is treated as the catch-all. If anything unexpected goes wrong, it’s assumed the customer will report it back to the organisation. Of course, that's not always the case — and certainly not ideal for the customer experience.
Catch all controls are monitoring, reviews or checks at the highest level to identify potential issues or causes for further investigation. This can include checks like system monitoring tools, reconciliations, reviewing trends of key health indicators or KPIs. Another approach is periodic meetings like Executive Management meetings to do a broad review and see whether there's any unexpected events, issues or performance matters that need further attention.
MECE – Mutually Exclusive & Collectively Exhaustive
This concept is a lot more complicated in practice than the others above. The concept of mutually exclusive and collectively exhaustive applies when taking a top-down view of process design.
The principle is ensuring that all events can be classified as something, and that there’s a way to manage each type of something. Each event is classified in a way that doesn’t duplicate or create confusion about the process that applies.
One example of MECE being applied using the ITIL definitions is classifying service requests, incidents and problems as the following:
-
Service Request: A request from a user for information/advice, for a standard change or for access to an IT service
-
Incident: An unplanned interruption to an IT service or reduction in the quality of an IT service
-
Problem: A cause of one or more incidents
Based on each event’s classification, the process will be designed to manage it accordingly. On a basic level, service requests are handled by the service desk as basic work item, and incidents are prioritised by the operations team to mitigate their impact. Problems are put into the backlog by the development team to remediate and prevent future occurrences.
There are often border cases. What if a user requested a reporting change to fix something considered to be a bug? This could be seen as a service request, incident (if it’s preventing them from completing what they require) and a problem all at once. A well-defined MECE approach provides clarity and consistency to how all these matters are handled to avoid duplication or things left unaddressed. What's most important is that it's understood by those responsible for it and they feel empowered to handle all situations that may arise.
These four concepts are a useful way to consider what is fit-for-purpose for each scenario, and then ensure an appropriate mix of different control types that complement each other.
-
Trigger points: ensure an action is taken when required and not "missed;
-
Gateways: ensure key steps and a minimum criteria are passed before proceeding;
-
Catch-alls: Identify causes for concern before they become major issues; and
-
MECE: Ensures clarity of surrounding processes with classifications to account for every situation.
The best controls will be well-thought-out, powerfully simple, and most importantly, have the buy-in and support of those responsible for managing them.